初版2009/08/05:最終更新日2009/08/05
rankとdense_rank
rankとdense_rankについて説明します。
説明するのがとても難しいので図を用いて説明したいと思います。以下のような表があるとします。
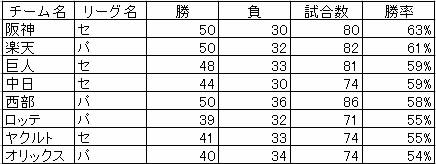
これは野球のセリーグとパリーグの順位表を適当に表(野球というテーブル名とする)にしたものです。
この表に対して、セリーグの一位とパリーグの一位を表示したい場合、どのようなSQLを書くでしょうか。
これは、rankを使用するととても簡単に取得することが出来ます。
rank() over (partition by 列名(…) order by 列名(…) は決まりの文法です。
まずpartition byでテーブルのレコードをどの列をキーとして分けるかを指定します。列は複数指定可能で、カンマ区切りで指定します。今回はセとパでわけたかったので、 partion by リーグ名 としました。
次に、order byで指定する列ですが、これはpartition by句でわけたレコードのグループ内で、order byを指定し、ソートをします。このソートの結果一番最初のレコードがランク1となります。
その次が2、その次が3…といった感じです。このようにレコードに対してランク付けするのがrank関数です。
最後にrankとdense_rankの違いを説明します。
この違いは非常に簡単で、ランク付けの方法が異なるだけです。ランク付けは、一位が2レコード存在する場合、その次のレコードのランクを3とするランク付けが、rankです。
これと異なり、一位が2レコード存在する場合、その次のレコードのランクを2とするランク付けが、dense_rankなのです。
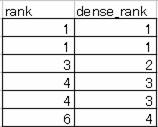
下図を見ると良くわかると思います。違いはこれしかありません。
説明するのがとても難しいので図を用いて説明したいと思います。以下のような表があるとします。
これは野球のセリーグとパリーグの順位表を適当に表(野球というテーブル名とする)にしたものです。
この表に対して、セリーグの一位とパリーグの一位を表示したい場合、どのようなSQLを書くでしょうか。
これは、rankを使用するととても簡単に取得することが出来ます。
select * from ( select 野球.*,rank() over (partition by リーグ名 order by 勝率 desc) as RANK from 野球 ) a where a.RANK = 1;というようにすることで、リーグ名ごとのランキング一位のチームのレコードを取得することが出来ます。
rank() over (partition by 列名(…) order by 列名(…) は決まりの文法です。
まずpartition byでテーブルのレコードをどの列をキーとして分けるかを指定します。列は複数指定可能で、カンマ区切りで指定します。今回はセとパでわけたかったので、 partion by リーグ名 としました。
次に、order byで指定する列ですが、これはpartition by句でわけたレコードのグループ内で、order byを指定し、ソートをします。このソートの結果一番最初のレコードがランク1となります。
その次が2、その次が3…といった感じです。このようにレコードに対してランク付けするのがrank関数です。
最後にrankとdense_rankの違いを説明します。
この違いは非常に簡単で、ランク付けの方法が異なるだけです。ランク付けは、一位が2レコード存在する場合、その次のレコードのランクを3とするランク付けが、rankです。
これと異なり、一位が2レコード存在する場合、その次のレコードのランクを2とするランク付けが、dense_rankなのです。
下図を見ると良くわかると思います。違いはこれしかありません。
partition byの省略
Information